Processing Genomics workflows require a variety of tools with distinct computing resources requirements. Some of these requirements are merely beyond the configuration of powerful workstations. High-performance clusters (HPC) offer the possibility to scale up computing resources to meet the increasing demands of these processes. However, maintaining the infrastructure of an on-premises HPC may not be a viable solution for many parities. A more cost-effective method is to provide computer resources dynamically by leveraging cloud computing. This strategy, combined with a powerful workflow manager such as NextFlow, allow researchers to execute their workflows locally and/or in the cloud with minimal friction.
AWS Batch
One of the available options to build a cloud-based HPC solution is AWS Batch from Amazon. It is a free service that can run batch jobs either periodically or on-demand in a usage-based pricing model.
AWS Batch can be broken down into the following components:
- Compute Environment defines computing resources for a specific workload.
- Job Queues allows binding of a specific task to one / more Compute Environment(s).
- Job Definition a template for one / more job(s) in the workload.
- Jobs binds a Job Definition to a specific Job Queue.
NextFlow supports submitting tasks (Job Definition) to AWS Batch via API calls. AWS Batch, in turns, maps each task with its resources requirements and store them as Jobs in the Job Queue awaiting for computing resources to become available.
Each Job Queue can be linked to one or more Compute Environnement that, with priority scheduling, distribute tasks of higher priorities to be executed on more than one Compute Environments.
A Compute Environnement is responsible for dynamically launch and scale compute resources based on tasks recruitments. It can be configured as an on-demand or spot Compute Environnement. In the on-demand model, there is no delay in launching and executing jobs. In contrast, in the spot model, the Compute Environnement is configured to launch Spot instances (i.e. price-reduced EC2 instances) once the Spot price drops below a specific percentage of the on-demand price.
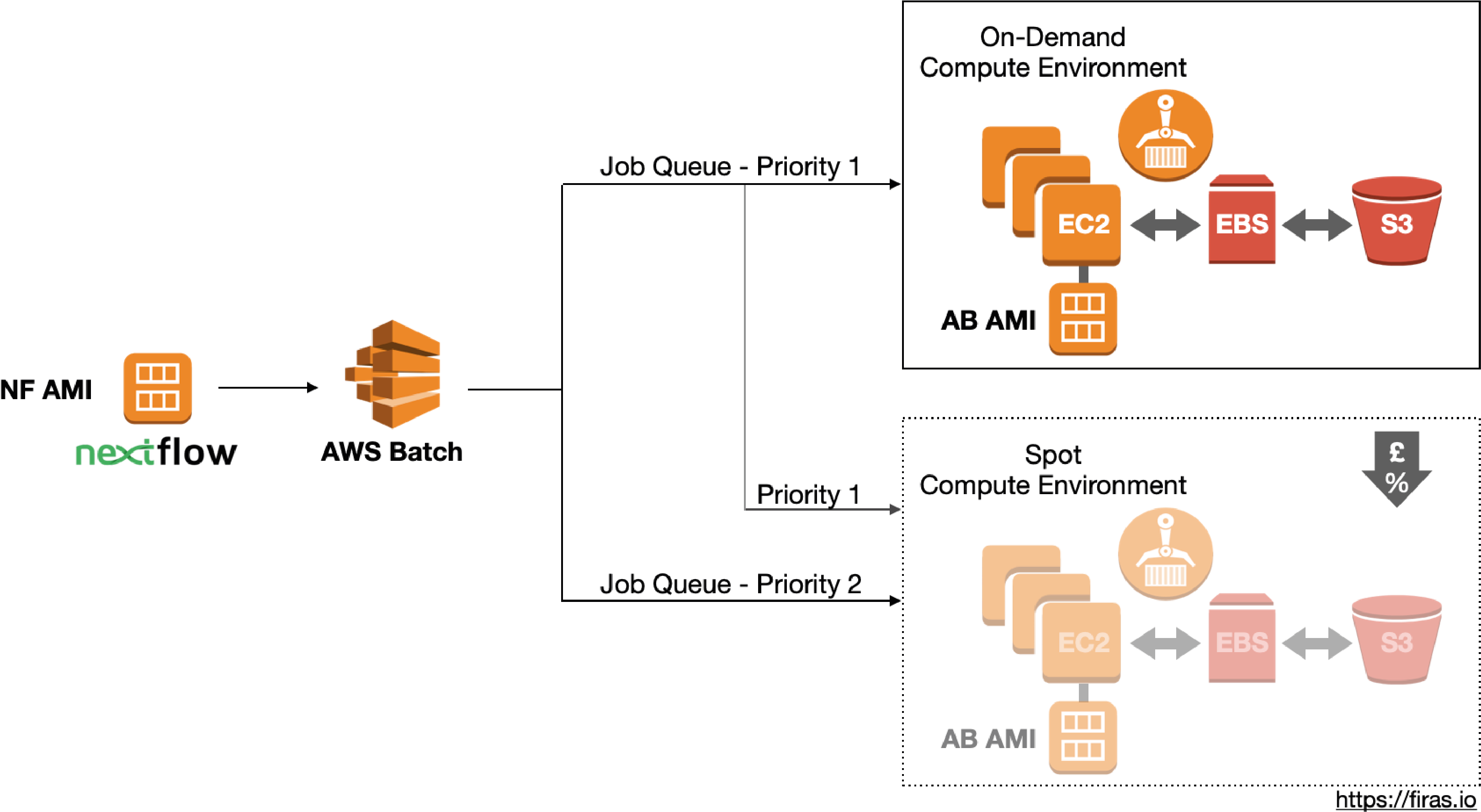
Once the compute resources become available, the Amazon Elastic Container Service (ECS) launches EC2 instances with a pre-built custom Amazon Machine Image (AMI) along with the pre-specified Amazon Elastic Block Store (EBS). In addition, it requests any named container from the Amazon Elastic Container Registry (ECR).
The EC2 mounts the S3 buckets to read the data, perform the process, and store the results back on S3. Depending on the volume of the data, the transfer between the S3 storage and the EBS may add additional processing time. This can be avoided by using Amazon FSx for Lustre which mounts the file system directly on the EC2 instance.
The Setup
Before running NextFlow on AWS Batch, we need to enable the service in our AWS account.
IAM user
This user account is used to manage the AWS Batch service. It needs the following privileges to be added within the IAM section:
- Schedule jobs using AWSBatch (
AWSBatchFullAccesspolicy). - Access S3 storage (
AmazonS3FullAccesspolicy) - Launch/terminate EC2 containers (
AmazonEC2FullAccesspolicy)
IAM Services Roles
In addition to the account above, the AWS Batch service needs to be configured with the following roles:
- Launching/terminating on-demand EC2 instances and access S3 storage:
AWSBatchServiceRolerole withAWSBatchServiceRolepermissionecsInstanceRolerole with bothAmazonS3FullAccessandAmazonEC2ContainerServiceforEC2Rolepermissions
- Grant the Spot Fleet permission to launch/terminate EC2 instances:
AmazonEC2SpotFleetRolerole with bothAmazonEC2SpotFleetTaggingRoleandAmazonEC2SpotFleetAutoscaleRolepoliciesAWSServiceRoleForEC2SpotFleetrole withAWSEC2SpotFleetServiceRolePolicypolicy
AWS Batch custom AMI (AB AMI)
This AMI serves as a template for every launched EC2 instance by AWS Batch. While it is possible to use many different instant types (see here), it is recommended to limit our choices to the ones that are compatible with ECS. The exact processor number and memory capacity are not significant at this stage as they are overridden by the Compute Environment at run-time. However, the attached EBS storage needs to be large enough to handle: the docker image, any genomic indices, input files, temp files and output files for any given process.
Once the AMI has started, we need to install awscli to enable read/write access to S3 storage. In addition, we need to increase the size of the Docker storage to match the size of the docker images to be used in the pipeline (see here). Finally, we need to create an image of this AMI to serve as a template for the ec2 instances launched by AWS Batch.
Compute Environment
When creating a Compute Environment, there are two options to consider: 1) the ‘Allowed instance types’: dictated by the hard requirements of our processes and 2) the ‘Provisioning model’ as ‘On-Demand’ vs ‘Spot’: dictated by our budget. In addition, we may specify the minimum and the maximum number of vCPUs. The maximum number of vCPUs is the number of all vCPUs allowed to be launched by the workflow. To get the number of instances that will launch of a given instance type, divide the maximum number by the number of vCPUs of that instance type. The minimum number of vCPUs is what the Compute Environment will maintain at all time, so setting it to zero helps avoid additional costs.
Job Queue
Each Job Queue can be connected to one or more Compute Environments. In addition, specifying the ‘Priority’ enables the distribution of higher priority jobs to multiple Compute Environment.
NextFlow AMI (NF AMI)
Although Nextflow supports scheduling jobs on the AWS Batch while running locally, it is not ideal for large workflows as it requires a constant connection for the duration of the workflow which could be hours to days. One possibility is to create a NextFlow job submission EC2 instance with a persistent EBS. This instance can be configured with NextFlow along with other productivity tools such as aws-cli, git, tmux, neovim, etc.
NextFlow Configuration
The final step of this setup is to configure NextFlow to work with AWS Batch. For this, we need to create a profile where the executor is awsbatch. In addition, we need to configure the options for queue, aws regions, access credentials, and the container to be used in each of the submitted processes.
Final remarks
This post provided an overview of how AWS Batch works and how to leverage it for running NextFlow pipelines in the cloud. It reflects my personal experience using the AWS Batch to run Genomic NextFlow pipelines in the cloud. For specific step-by-step guide, one can check the AWS Batch User Guide, and the NextFlow documentation. For reference, my configuration can be found in my dedicated Github repository here.